



Technical Abstract
Unlocking Value from Unstructured Documents Using Machine Learning: a Geochemistry Case Study, Us Gulf of Mexico
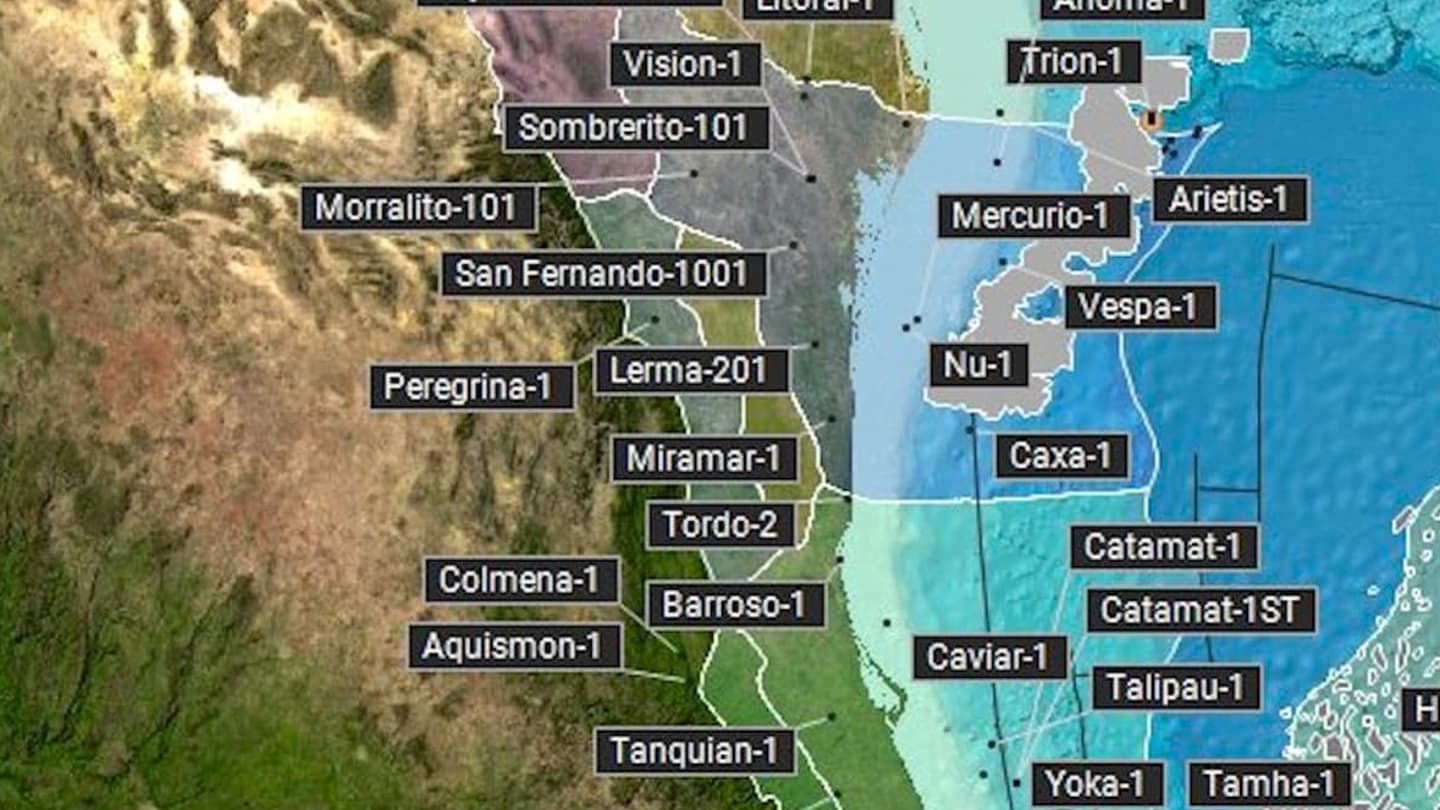
Back to Technical ContentOver two million files, containing geochemical information, have been collected from tens of thousands of wells drilled during decades of exploration in the Gulf of Mexico (GOM) and are available to geoscientists in the public domain. While these files represent a vast knowledgebase covering subsurface geology and petroleum systems, data extraction, systematic compilation and quality control was previously too cumbersome to harness the full power of the data to make basin wide correlations, uncover new trends and ultimately opportunities. A novel machine learning approach was employed to automate data classification and extraction across three protraction areas for all public domain geochemistry and PVT documents to provide a single consistent database from un-tagged, legacy formats stored in entirely different subfolders. The resulting database provides the ability to rapidly screen and integrate data from multiple disciplines over a large scale, in terms of data volume as well as geospatial coverage. This in turn opens up petroleum systems analysis work to a wider user base by acting as a bridge between disciplines, such as reservoir engineering and geochemistry. Removing disciplines from silos is critical to enhancing collaboration between teams, improving efficiencies around specific workflows such as fluid property prediction and therefore reducing uncertainty.
Download Resource 
Publications
EAGE - European Association of Geoscientists and EngineersAuthors
Matthew Fry, Sijibomioluwa Badejo, Jamie Richardson (CGG) ; Kenneth Petersen, Holger Justwan (Hess)